
📰 Automated News Web Scraper with Python using Scrapy and FastAPI🕸🕷

Photo: Suzy Hazelwood, https://www.pexels.com/@suzyhazelwood
At the end of the intensive stage of the Platzi Master Program, the students have to develop a group project that involves several disciplines: Frontend-Backend development, and DataScience.
My team and I developed AlwaysUpdate which is a digital newspaper that automatically compiles daily news from different news portals, does a sentiment analysis of the text, and classifies its content as positive, neutral, or negative.
As the project's Data Scientist, I developed the automated web crawler-scraper, and the sentiment analysis functionality, all served with a FastAPI REST API deployed in Google Cloud Platform.
I had the opportunity to work with great people in this particular project, that allowed us to build a very nice application in just 2 weeks.
My intention in this post is to show how I developed a complete automated news web scraper using Python and the Google Cloud Platform.
You can see the project's Notion documentation here: https://www.notion.so/AlwaysUpdate-043bae4a8356407c8d66e3333df10007
You can see the DataScience documentation here: https://www.notion.so/Documentation-DataScience-d2523911e82848b9a2f69acef31386d0
Features
- Automated news web crawling-scraping executed several times per day.
- Sentiment analysis of each article.
- Database storing of category-labeled news articles.
- Data Science REST API that could be consume by the backend as a client.
Technologies
- Python
- Scrapy: Web Crawling and Scraping Framework
- FastAPI: REST API FrameWork
- SQL Alchemy: ORM
- MySQL - Google Cloud SQL
- Docker - Deployment in Google Cloud Run
- Google Scheduler

Architecture
The entire application was developed using the microservices architectural style, that is an approach where the web app is build with a set of small services, each one running independently, that means each one has independent processes, with communication using the HTTP protocol.
Generally, these small services are deployed as a REST API.
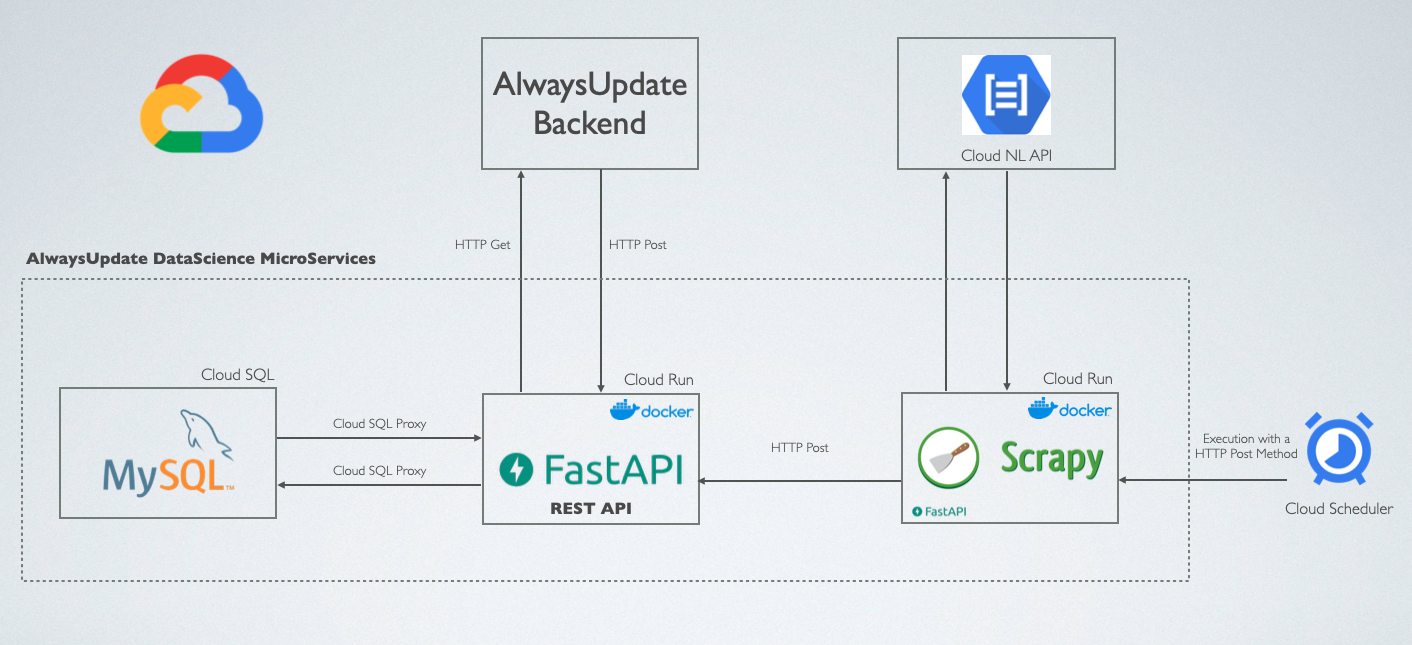
In the diagram above, it is possible to see how the Data Science services communicate between each other, and with the backend API.
News Categories
- Politics
- Economy
- Sports
- Culture
- Entertainment
- Technology
- Health & Lifestyle
- General
- Country
Web Scraper
The scraper takes several starting URLs (journal's webpages), and finds the links to the news articles, this creates a link network, you can imagine it like a spiderweb. After that, it visits each URL, extracts the information, calculates the sentiment polarity, and saves the labeled data in the database using the REST API. The news articles labels are the categories listed above.
In fact, the last paragraph describes, superficially, how Scrapy works; this framework is a powerful tool for web scraping because is asynchronous, that means, the scraper visits the URL at "the same time".
Scrapy works with Spiders, which are classes that define how the scraper will extract the information.
Therefore, I created a Spider for every site which we wanted to scrape, that allowed me to personalize the logic according to each site.
In addition, Scrapy has pipelines where it's possible to put code before, during, and after the data extraction of each URL.
For example, the following code is for one of the spiders I created for the project, using XPath to access the DOM content.
import scrapy
import pandas as pd
from . import utils
# xpath
# links = //div[@class="seccion"]//a[@class="boton page-link"]/@href
# title = //div[@class="content_grid_margin"]//h1[@class="titulo"]/text()
# Subtite = //div[@class="content_grid_margin"]//div[@class="lead"]/p/text()
# publication_date = //div[@class="articulo-autor"]//div[@class="fecha-publicacion-bk"]/span/text()
# body = //div[@class="articulo-contenido"]//div[@class="modulos"]/p/text()
# img url = //div[@class="articulos"]//div[@class="figure-apertura-bk"]//meta[@itemprop="url"]/@content
class SpiderElTiempo(scrapy.Spider):
name = 'eltiempo'
start_urls = [
'https://www.eltiempo.com/cultura/entretenimiento',
'https://www.eltiempo.com/politica',
'https://www.eltiempo.com/deportes',
'https://www.eltiempo.com/tecnosfera',
'https://www.eltiempo.com/salud',
'https://www.eltiempo.com/vida',
'https://www.eltiempo.com/economia',
'https://www.eltiempo.com/cultura'
]
custom_settings = {
#'FEED_URI': 'eltiempo.json',
'FEED_FORMAT': 'json',
'FEED_EXPORT_ENCODING': 'utf-8'
}
def parse(self, response):
links = response.xpath('//div[@class="seccion"]//a[@class="boton page-link"]/@href').getall()
for link in links:
yield response.follow(link, callback = self.parse_link, cb_kwargs={'url': response.urljoin(link)})
def parse_link(self, response, **kwargs):
link = kwargs['url']
title = response.xpath('//div[@class="content_grid_margin"]//h1[@class="titulo"]/text()').get()
subtitle = response.xpath('//div[@class="content_grid_margin"]//div[@class="lead"]/p/text()').get()
article_date = response.xpath('//div[@class="articulo-autor"]//div[@class="fecha-publicacion-bk"]/span/text()').get()
body_html = response.xpath('//div[@class="articulo-contenido"]//div[@class="modulos"]/p/text()').getall()
body = utils.format_body(body_html)
image_url = response.xpath('//div[@class="articulos"]//div[@class="figure-apertura-bk"]//meta[@itemprop="url"]/@content').get()
category_translator = {
'politica': 1,
'deportes': 3,
'tecnosfera': 6,
'salud': 7,
'vida': 7,
'economia': 2,
'cultura': 4,
'entretenimiento': 5
}
category = 8
try:
cat_str = link.split('.com/')[1].split('/')[0]
cat_str_ent = link.split('.com/')[1].split('/')[1]
if cat_str_ent=='entretenimiento':
category = 5
else:
category = category_translator[cat_str]
except KeyError:
print('Category not listed')
date = pd.to_datetime('today')
yield {
'id': 0,
'article_url': link,
'title': title.rstrip(),
'subtitle': subtitle.rstrip(),
'article_date': article_date.strip(),
'body': body,
'image_url': image_url,
'category_id': category,
'journal_id': 1,
'scraping_date': str(date)
}If you want to check the complete scraper code go to:
 jasantosm
jasantosmAutomation
The team decided to execute the scraper three times per day to check for news updates, therefore the scraper has being executed automatically every day at 7am, 12pm, and 7pm.
To do that, I used Google Scheduler, that is a Google service which sends a HTTP POST request at a fixed time, so I put a FastAPI POST function on front of the scraper to get the POST request, and launch the scraper.
Sentiment Analysis
The sentiment analysis is a way to determine and quantify the actitud of the writer, so it's possible to get a number for the sentiment and subjectivity of the text.
At the beginning I used Google Cloud NL API for this app's functionality, however, it has a cost that we couldn't afford as a team, so I switched to Python's library TextBlob that is open source and free to use.
TextBlob's sentiment, or polarity, is a float within the range [-1.0,1.0], so we used this number as a positivity classification for the news scraped. From -1.0 to -0.25 is negative, from -0.24 to 0.25 is neutral, and from 0.26 to 1.0 positive.

The sentiment function is called in the pipeline of the Scrapy spider:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
import requests
import json
import pandas as pd
from itemadapter import ItemAdapter
from . import sentiment
class NewsCrawlerScraperPipeline(object):
def open_spider(self, spider):
spider.crawler.stats.set_value('total_articles_added', 0)
def process_item(self, item, spider):
s = sentiment.get_polarity(sentiment.clean_text(item['body']))
item['score'], item['magnitude'] = s.polarity, s.subjectivity
if item['score']>0 and item['score']<0.2:
item['sentiment_classification'] = 'neutral'
if item['score']>=-1 and item['score']<=0:
item['sentiment_classification'] = 'negative'
if item['score']>=0.2 and item['score']<=1:
item['sentiment_classification'] = 'positive'
api_url = os.environ['API_URL']
response = requests.post(api_url+'articles/', data = json.dumps(ItemAdapter(item).asdict()))
response_dict = json.loads(response.text)
try:
if response_dict['article_url']:
response_dict['detail'] = 'No detail at all'
except KeyError:
print('KeyError with detail\n')
try:
total = int(spider.crawler.stats.get_stats()['total_articles_added'])
if response_dict['detail'] != 'Article already registered':
spider.crawler.stats.set_value('total_articles_added', total+1)
except KeyError:
print('KeyError in the add to the counter\n')
return item
def close_spider(self, spider):
stats_body = spider.crawler.stats.get_stats()
stats_dict = {
'id': 0,
'response_count': stats_body['downloader/response_count'],
'start_time': str(pd.to_datetime(str(stats_body['start_time'])).tz_localize('UTC').tz_convert('America/Bogota'))[:-6],
'finish_time': str(pd.to_datetime('today')),
'memory_usage_max': stats_body['memusage/max'],
'total_articles_added': stats_body['total_articles_added'],
'scraping_date': str(pd.to_datetime('today')),
'spider': str(spider.name)
}
api_url = os.environ['API_URL']
requests.post(api_url+'scraper_stats/', data = json.dumps(ItemAdapter(stats_dict).asdict()))REST API
Our REST API was developed with FastAPI which is a powerful and very easy to use Python Web Framework. I have to say that I think FastAPI is better than Flask or Django, for several reasons, take a look to this page: https://fastapi.tiangolo.com/alternatives/
If you don't know what is a REST API check this link out: https://en.wikipedia.org/wiki/Representational_state_transfer
The goal of the API is to allow interaction between the backend, and the scraper with the news MySQL database, continue reading to see the DB Schema.
In addition, the web scraper operates independently of the REST API in order to avoid that the API crashes when the scraper does.
Accordingly a scraper is an unstable software that depends of the scraped webpage code which is not in our control.
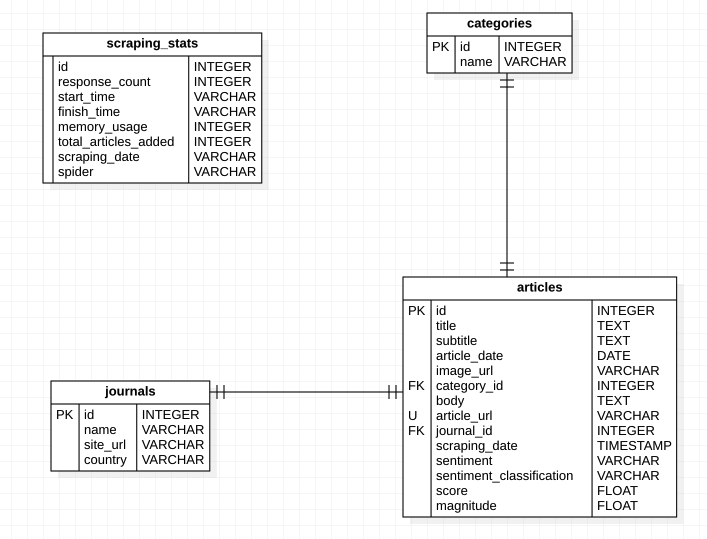
FastAPI is very well integrated with SQLAlchemy so I used this Object Relational Mapper, ORM, to access the database.
Here an example of the API Router Code:
from typing import List
from fastapi import Depends, APIRouter, HTTPException
from sqlalchemy.orm import Session
from .. import articles_crud, schemas
from ..database import SessionLocal
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
router = APIRouter()
@router.post("/articles/", response_model=schemas.Article)
async def create_article(article: schemas.Article, db: Session = Depends(get_db)):
db_article = articles_crud.get_article_by_url(db, article_url=article.article_url)
if db_article:
raise HTTPException(status_code=400, detail="Article already registered")
return articles_crud.create_article(db=db, article=article)
@router.get("/articles/", response_model=List[schemas.Article])
async def read_articles(db: Session = Depends(get_db)):
return articles_crud.get_articles(db=db)
@router.get("/articles-joined/", response_model=List[schemas.ArticleJoined])
async def read_articles_joined():
return articles_crud.get_articles_text()
@router.get("/articles-joined/{date}", response_model=List[schemas.ArticleJoined])
async def read_articles_joined_by_date(date: str):
return articles_crud.get_articles_by_date(date)To see the whole code go to:
jasantosmDeployment
The project had to be functional and online, so I had to deploy it somehow. To do that I decided to use Docker that is a container management software.
The container packs all the libraries and resources that the application requires, however, the power of the Docker containers is that are independent of the operating system, so once you have your app developed using Docker you can deploy it to production very easily.
Indeed, a container is like a virtualize Linux system, but created by Docker only for the application.
Docker configuration file is called Dockerfile. Here this project's Dockerfile:
# Use the official Python image.
# https://hub.docker.com/_/python
FROM python:3.7
ENV APP_HOME /app
WORKDIR $APP_HOME
# Install manually all the missing libraries
RUN apt-get update
# Install Python dependencies.
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
ENV TZ=America/Bogota
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
# download the cloudsql proxy binary
RUN wget https://dl.google.com/cloudsql/cloud_sql_proxy.linux.amd64 -O cloud_sql_proxy
RUN chmod +x cloud_sql_proxy
COPY run.sh run.sh
COPY credentials.json credentials.json
# Copy local code to the container image.
COPY . .
RUN chmod +x run.sh
# Run the web service on container startup.
#RUN ./run.sh
EXPOSE 8080
CMD ["./run.sh"]
As you can see in the architecture showed above, the API and the Scraper were packed in separate containers, as I told you before, they are independent services. To put them online I used Google Cloud Run because its CLI Toolkit is very easy to use for deployment with commands very similar to Docker ones.
With the Scraper and API deployed the Backend API can consume the news scraped.
In this post I showed you how I developed a complete automated news web scraper using Python with Scrapy and FastAPI as main frameworks, and of course, the Google Cloud Platform for deployment.
Thank you for reading!